An Ontology is a schema that defines how content should be organized, classified, and enriched within Sync. Ontologies specify what types of content exist (categories), what structured data should be extracted from or asssociated with them (metadata queries), and how that data should be validated. Importantly, metadata defined in ontologies can optionally be passed to AI models as context, making them significantly smarter and more accurate when processing your specific content.
An ontology consists of three interconnected components:
Categories: Content types or classifications (e.g., "Contract", "Invoice", "Research Paper")
Metadata Queries: Fields that can be extracted from content (e.g., "Effective Date", "Author Name", "Total Amount")
Query Bindings: Relationships that link metadata queries to categories with rules about requirements and uniqueness
Together, these components enable Sync to:
- Validate metadata during upload
- Extract structured data from unstructured documents
- Enable intelligent versioning of content
- Power SQL-queryable metadata for analytics
- Provide context to AI models for smarter processing
Ontologies are reusable—a single ontology can be used across multiple dataspaces, ensuring consistent classification and extraction rules.
Categories represent the types of content in your system. Each category has:
- Name: Human-readable identifier (e.g., "Legal Contract")
- Description: Purpose and scope of the category
- Instructions: Optional AI guidance for classification
Subcategories via Pipe Syntax: Categories support hierarchical classification using pipe notation:
"Contract | Master Service Agreement"
"Contract | Employment Agreement"
"Invoice | Purchase Order"
"Invoice | Credit Memo"This allows you to create taxonomies with parent-child relationships. The hierarchy is semantic—Sync treats these as separate categories but preserves the relationship for filtering and organization.
Metadata queries define fields that can be extracted from content. Each query includes:
- Name: Field identifier (e.g., "Effective Date")
- Description: What this field represents
- Data Type: STRING, SHORT_STRING, NUMBER, BOOLEAN, or DATE
- Instructions: AI prompt explaining how to extract this field
Example Metadata Query:
{
"name": "Effective Date",
"description": "The date when the contract becomes effective",
"dataType": "DATE",
"instructions": "Extract the effective date from the contract. Look for phrases like 'Effective as of', 'Effective Date:', or 'This agreement shall commence on'. Return in ISO 8601 format (YYYY-MM-DD)."
}The instructions are crucial—they're provided to the AI model during ingestion to guide accurate extraction.
Query bindings connect metadata queries to categories and specify:
- Required: Must this field be provided/extracted?
- Unique Index Element: Is this field part of content versioning?
Example Binding:
{
"categoryId": "cat-contract-uuid",
"metadataQueryId": "mq-effective-date-uuid",
"required": true,
"uniqueIndexElement": true
}This binding means: for all content in the "Contract" category, "Effective Date" must be provided and will be used to identify different versions of the same contract.
Sync uses unique index elements to automatically group different versions of the same content together.
When you mark metadata queries as uniqueIndexElement: true, Sync uses those fields to generate a version identifier. Content with the same values for all unique index elements are considered different versions of the same underlying document.
Example: Contract Versioning
Ontology configuration:
{
"category": "Contract",
"boundMetadataQueries": [
{
"name": "Customer Name",
"uniqueIndexElement": true,
"required": true
},
{
"name": "Contract Type",
"uniqueIndexElement": true,
"required": true
},
{
"name": "Effective Date",
"uniqueIndexElement": false,
"required": true
}
]
}Content uploads:
// Version 1
{
"fileName": "Acme-MSA-2024.pdf",
"metadata": {
"Customer Name": "Acme Corp", // Unique index
"Contract Type": "MSA", // Unique index
"Effective Date": "2024-01-01" // NOT unique index
}
}
// Version 2 (same customer, same type, different date)
{
"fileName": "Acme-MSA-2024-Amended.pdf",
"metadata": {
"Customer Name": "Acme Corp", // Same
"Contract Type": "MSA", // Same
"Effective Date": "2024-06-15" // Different
}
}These two documents are automatically linked as Version 1 and Version 2 of the same contract because they share the same unique index values (Customer Name + Contract Type).
Querying Versions:
-- Get all versions of Acme Corp MSA
SELECT
id,
file_name,
metadata->>'Effective Date' as effective_date,
version_string
FROM content
WHERE category_id = 'cat-contract-uuid'
AND metadata->>'Customer Name' = 'Acme Corp'
AND metadata->>'Contract Type' = 'MSA'
ORDER BY metadata->>'Effective Date' DESC;Ontologies are created via the Admin API using a bulk update operation that handles all components atomically.
POST https://cloud.syncdocs.ai/api/accounts/{accountId}/ontologies
Authorization: Bearer <token>
Content-Type: application/json
{
"name": "Legal Documents",
"description": "Classification and extraction schema for legal content"
}Response:
{
"id": "ont-12345678-uuid",
"name": "Legal Documents",
"description": "Classification and extraction schema for legal content",
"createdAt": "2024-10-28T10:00:00Z"
}Use the bulk update API to add categories, metadata queries, and bindings in a single transaction:
POST https://cloud.syncdocs.ai/api/accounts/{accountId}/ontologies/{ontologyId}/bulk
Authorization: Bearer <token>
{
"operations": {
"metadataQueries": {
"create": [
{
"tempId": "temp-effective-date",
"name": "Effective Date",
"description": "Contract effective date",
"dataType": "DATE",
"instructions": "Extract the effective date in ISO 8601 format"
},
{
"tempId": "temp-parties",
"name": "Contracting Parties",
"description": "Names of all parties to the contract",
"dataType": "STRING",
"instructions": "List all parties to this contract, separated by commas"
}
]
},
"categories": {
"create": [
{
"tempId": "temp-contract",
"name": "Contract | Master Service Agreement",
"description": "Master service agreements",
"instructions": "Documents establishing ongoing service relationships",
"boundMetadataQueries": [
{
"id": "temp-effective-date",
"binding": { "required": true, "uniqueIndexElement": false }
},
{
"id": "temp-parties",
"binding": { "required": true, "uniqueIndexElement": true }
}
]
}
]
}
}
}Ontologies are designed to evolve over time. You can start with basic categories and metadata queries, then progressively expand as you discover new extraction needs.
Workflow:
- Start Simple: Create basic categories and a few essential metadata queries
- Upload Content: Begin ingesting documents
- Review Results: Examine extracted metadata quality
- Add Queries: Identify additional fields worth extracting
- Refine Instructions: Improve AI extraction prompts based on results
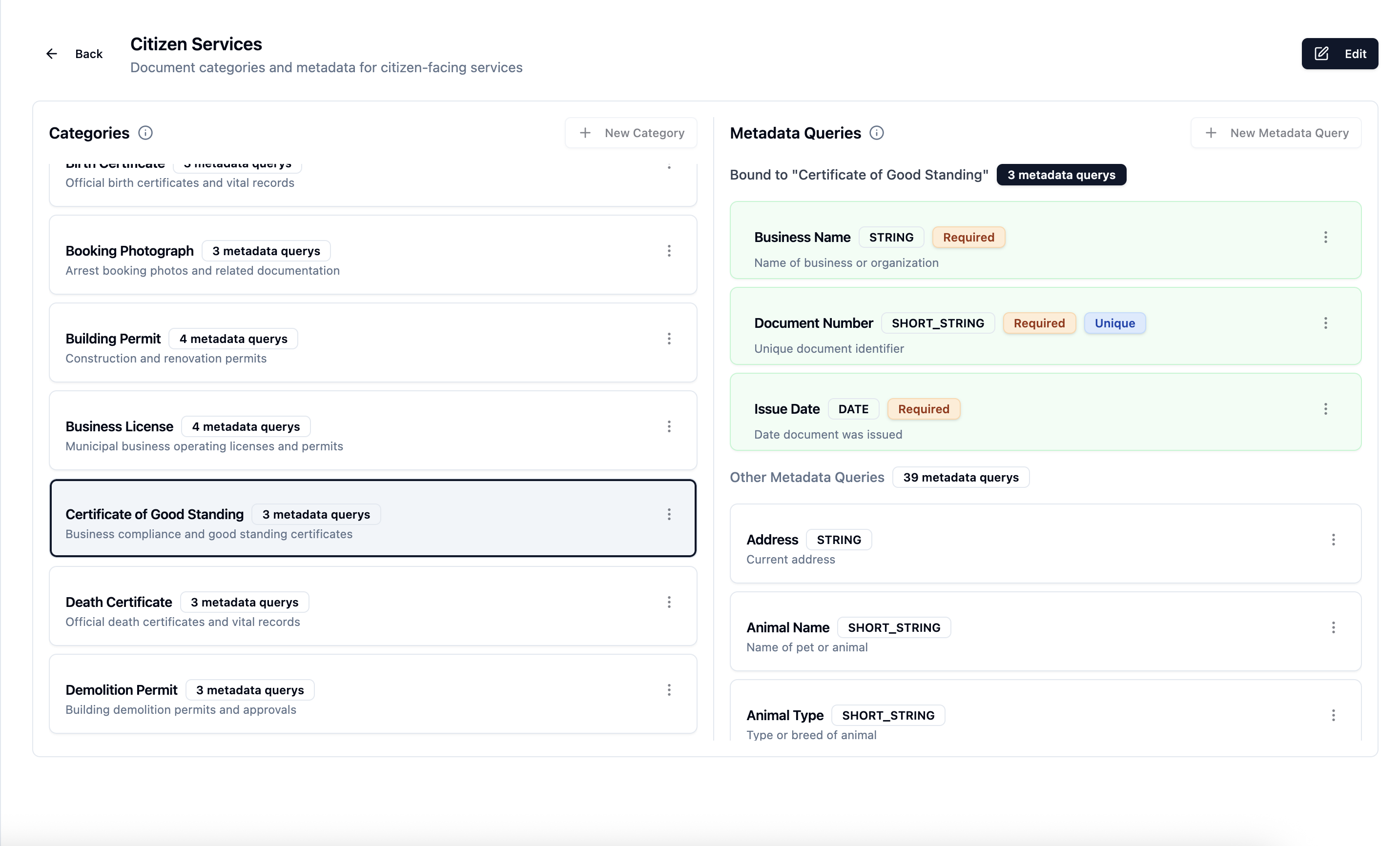 Screenshot: Ontology list view in Sync Cloud showing categories and metadata queries
Screenshot: Ontology list view in Sync Cloud showing categories and metadata queries
The document query editor provides an interactive interface for designing and testing metadata queries:
- Upload a sample document
- Write extraction instructions
- Test the query against the document
- Review AI-extracted results
- Refine instructions until accuracy is high
- Save the query to your ontology
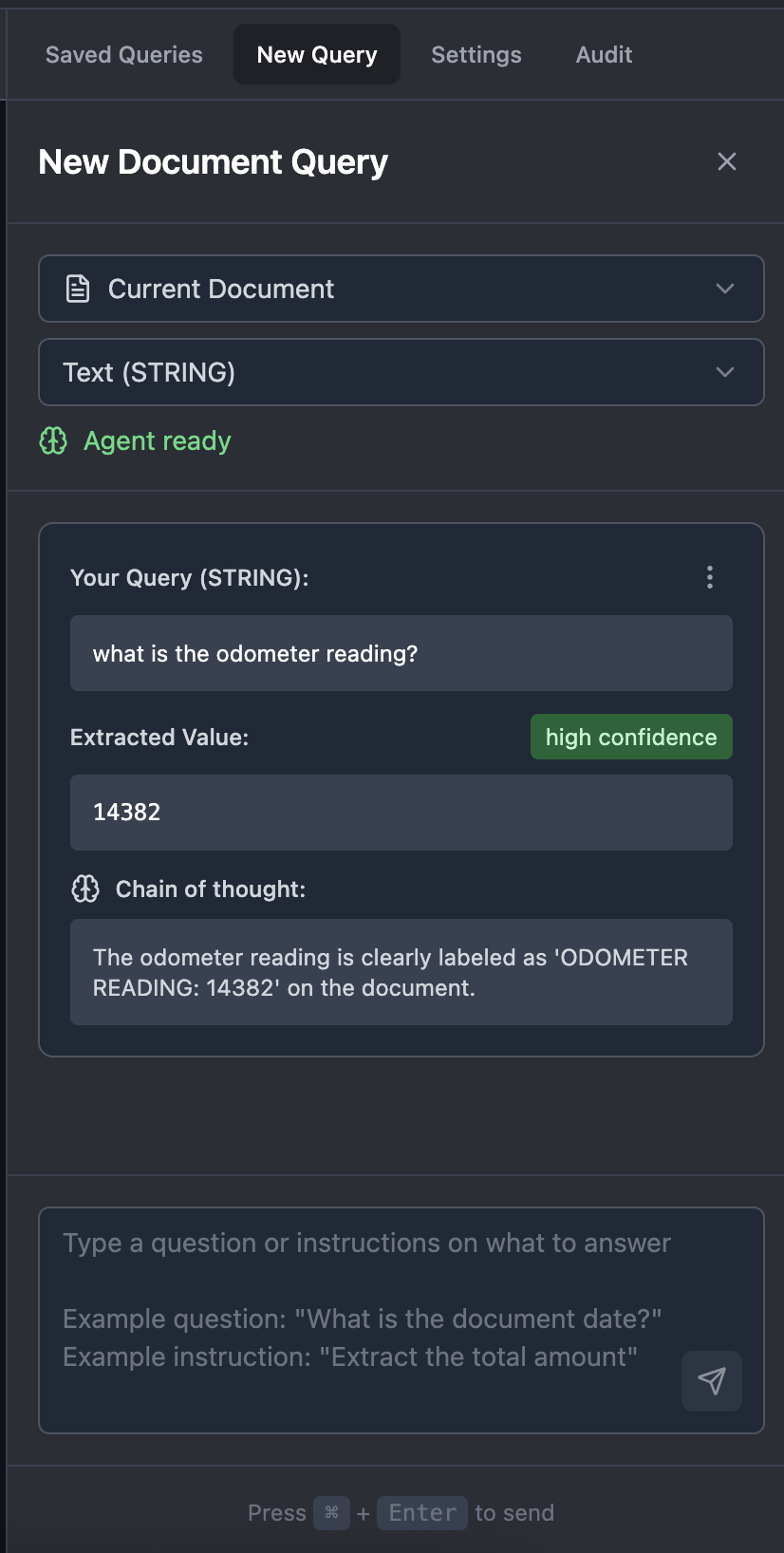 Screenshot: Query editor with sample document preview and extraction results
Screenshot: Query editor with sample document preview and extraction results
For complex ontologies, you can define the entire schema in Excel and upload it at once.
Excel Format:
- Sheet 1: Categories: name, description, instructions
- Sheet 2: Metadata Queries: name, description, dataType, instructions
- Sheet 3: Query Bindings: categoryName, metadataQueryName, required, uniqueIndexElement
Upload:
POST https://cloud.syncdocs.ai/api/accounts/{accountId}/ontologies/{ontologyId}/import
Content-Type: multipart/form-data
Authorization: Bearer <token>
{
"file": <Excel file>
}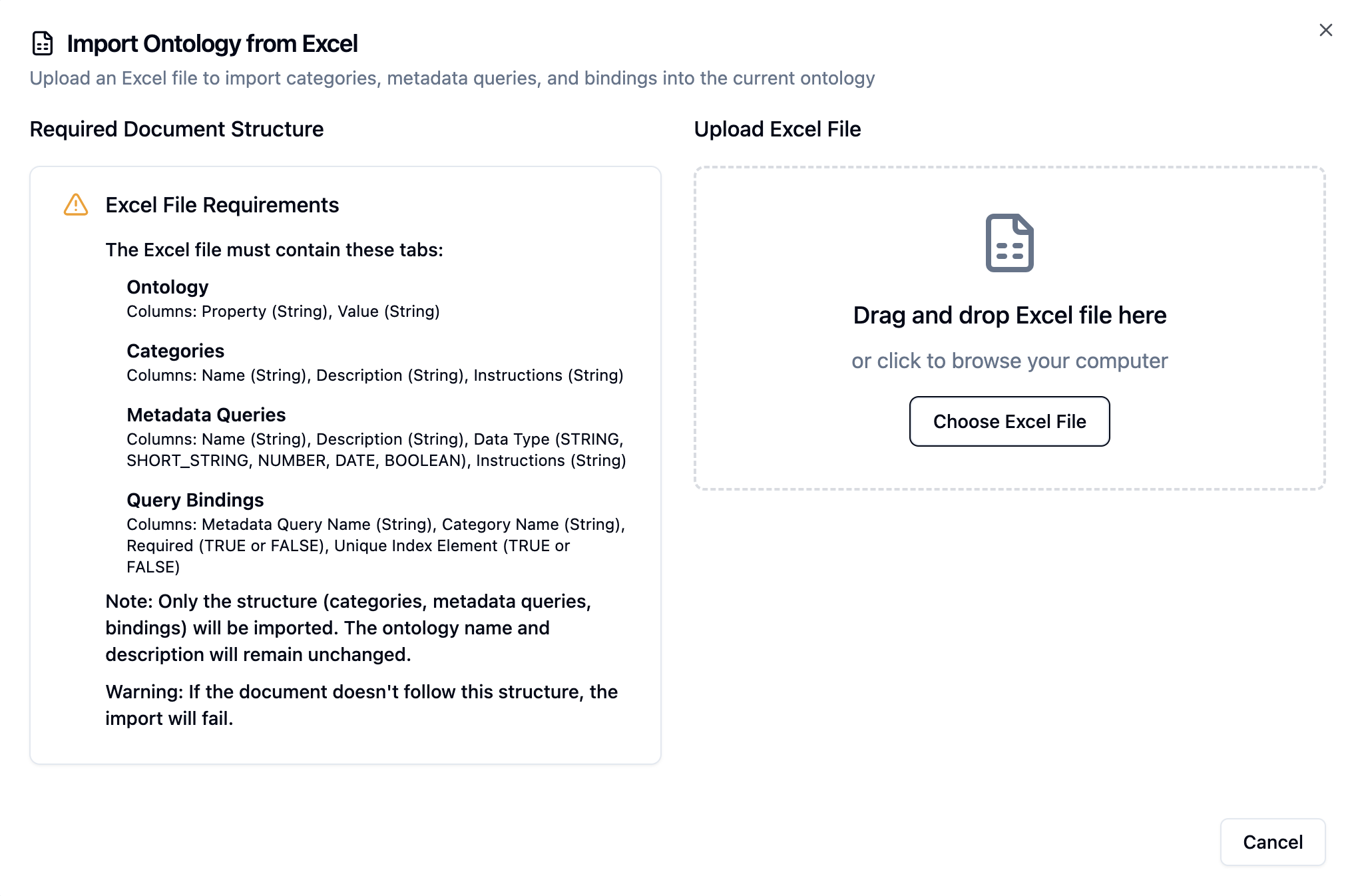 Screenshot: Excel upload interface with template download option
Screenshot: Excel upload interface with template download option
The Sync Cloud UI provides comprehensive views of your ontologies:
- Category Tree: Hierarchical view of all categories and subcategories
- Metadata Query Library: All defined queries with usage statistics
- Binding Matrix: Visual grid showing which queries apply to which categories
- Understand Content - See how ontologies validate and enrich content
- Explore Dataspaces - Associate ontologies with dataspaces
- Learn about Queries - Query extracted metadata
- API Reference - Complete ontology API documentation