Sync's platform architecture is designed to make it easy to build document AI appplications while maintaining complete data isolation, security, and scalability. This document explains how the platform works under the hood.
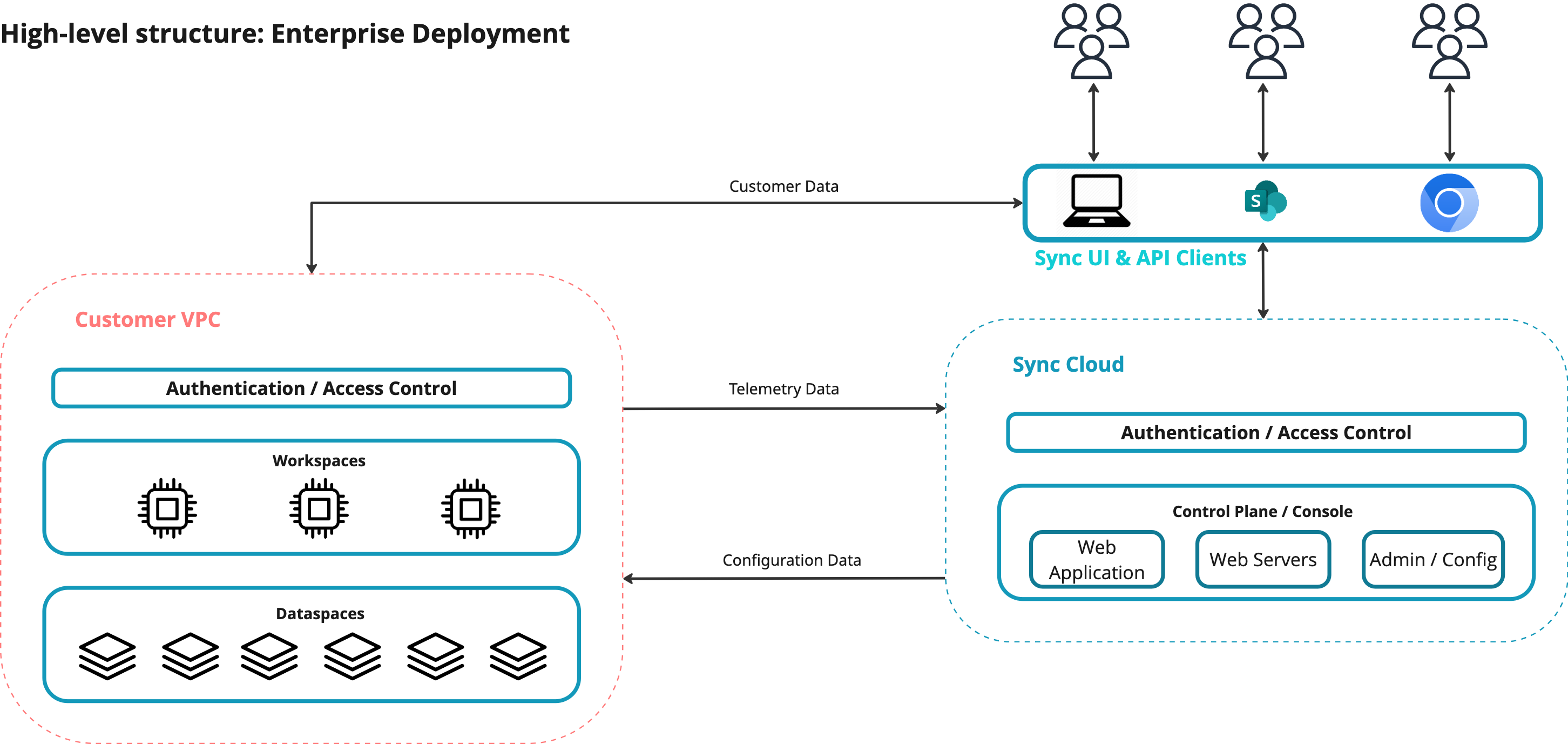
Sync uses a three-tier architecture that separates concerns between global management, customer data storage, and computational processing:
- Control Plane - Centralized management and orchestration (multitenant, hosted by Sync)
- Data Plane - Isolated storage for customer content and metadata (per customer, in their VPC)
- Compute Plane - Stateless processing clusters that execute queries and workflows (per customer, in their VPC)
This separation enables Sync to provide a seamless user experience while ensuring complete data isolation between customers and allowing independent scaling of storage and compute resources.
Customers using our Standard edition have their VPC and resources provisioned and managed by Sync in a Sync-owned cloud account. Customers in our enterprise offering can instead have this within their own cloud accounts.
__  __
__
The Control Plane is the central nervous system of Sync. It manages all administrative operations, user authentication, resource provisioning, and orchestration—but crucially, it never stores customer content data.
- Accounts & Users: Authentication, permissions, and access control
- Ontologies: Schema definitions for how content should be classified and structured
- Categories & Metadata Queries: Content classification taxonomies and custom field definitions
- Workflows: Task definitions and execution graphs for document processing pipelines
- Agents: AI assistant configurations with custom instructions and models
- Libraries: External content sources and their scraping configurations
- Dataspaces: Storage segment definitions and their ontology associations
- Workspaces: Compute cluster provisioning and lifecycle management
The Control Plane explicitly does not have access to:
- Customer document files
- Document content or extracted text
- Query results or AI responses
- Dataspace database content
- Any customer business data
The control plane can be accessed through our UI or account admin APIs, both available at https://cloud.syncdocs.ai
Customer data and processing live in isolated Virtual Private Clouds (VPCs), completely separate from the Control Plane and from other customers. This architecture ensures both network- and VM-level isolation and supports both SaaS (Sync's AWS account) and PaaS (customer's AWS account) deployments.
The Data Plane consists of isolated storage resources for each customer. The data plane itself can be divided into multiple Dataspaces, each of which can be thought of as an isolated "drive" or "bucket" of content.
Under the hood, Sync's platform transparently manages a composition of best-in-class storage solutions to efficiently handle storage of unstructured data, structured data and vector embeddings so users only have to worry about business logic. Customers can chose between transaction-optimized and analytics-optimized dataspaces; the former use transactional database technology to enable fast querying and operations while the latter decouple storage from compute to enable large-scale applications or cost-effective long-term storage (i.e. a data lakehouse architecture).
In both cases, customers are able to access and modify the underlying data and its derivatives (such as text output, metadata or embeddings) through any of the following three mechanisms:
- A RESTful API
- ANSI-SQL compliant connection (read only)
- The APIs of the underlying cloud provider (e.g. S3 API for unstructured data stored in an AWS environment)
Workspaces are ephemeral-state processing clusters deployed as Kubernetes clusters in customer VPCs. They execute all document processing, queries, and AI operations, as well as host the RESTful API to acces data within the VPC.
- Stateless: Can be destroyed and recreated without data loss
- Multi-dataspace: One workspace can access multiple dataspaces
- Independent Scaling: Add/remove or rescale workspaces without affecting storage
- Isolated: Each workspace runs in its own namespace within the VPC
One of Sync's key architectural features is how configuration created in the Control Plane seamlessly propagates to all Workspace instances in real-time. Organizatinos will typically have global configuration that should apply to several if not all workspaces and dataspaces within their domain of control (for example, a common ontology for defining daata classification or a common set of permissions).
Sync automatically manages the configuration of workspaces with appropriate data within workspaces. That way, users can define these configuration objects once and reuse them across one or more workspaces as needed.
Sync's document ingestion is a two-phase process: first, content is added to a dataspace with optional metadata; then, users explicitly trigger ingestion to make the document AI-ready. This separation provides flexibility for different workflows and ensures users have control over when processing occurs.
Content can be added to a dataspace with any metadata you want—or none at all. Sync doesn't enforce a schema unless you configure ontology-based validation.
POST https://sws-12345678.cloud.syncdocs.ai/api/content/sds-87654321
Content-Type: multipart/form-data
{
"file": <binary data>,
"metadata": {
"customerName": "Acme Corp",
"contractType": "Master Service Agreement",
"effectiveDate": "2024-01-15",
"annualValue": 250000,
"signedBy": "Jane Smith",
"internalId": "CONT-2024-0042",
"customField1": "any value",
"customField2": ["can", "be", "arrays"]
}
}Response:
{
"contentId": "550e8400-e29b-41d4-a716-446655440000",
"fileName": "MSA-AcmeCorp.pdf",
"fileFormat": "pdf",
"dataspaceId": "sds-87654321",
"categoryId": null,
"metadata": {
"customerName": "Acme Corp",
"contractType": "Master Service Agreement",
"effectiveDate": "2024-01-15",
"annualValue": 250000,
"signedBy": "Jane Smith",
"internalId": "CONT-2024-0042",
"customField1": "any value",
"customField2": ["can", "be", "arrays"]
},
"status": "uploaded",
"createdAt": "2024-10-28T10:30:00Z"
}At this stage:
- ✅ File stored in blob storage
- ✅ Metadata stored in SQL-compliant store
- ✅ Content record created
- ❌ Not yet searchable
- ❌ No text extraction
- ❌ No AI processing
If your dataspace has an ontology with defined metadata queries (fields), Sync can validate uploaded metadata:
// Ontology definition (in Control Plane)
{
"ontologyId": "ont-uuid",
"metadataQueries": [
{
"id": "mq-effective-date",
"key": "effectiveDate",
"displayName": "Effective Date",
"type": "date",
"required": true,
"validationRule": "must be in ISO 8601 format"
},
{
"id": "mq-amount",
"key": "annualValue",
"displayName": "Annual Contract Value",
"type": "number",
"required": false
}
]
}With validation enabled, uploads are checked against the schema, and invalid metadata is rejected.
Once content is uploaded, users explicitly call the ingestion endpoint to process the document and make it AI-ready.
POST https://sws-12345678.cloud.syncdocs.ai/api/content/sds-87654321/550e8400.../ingest?workflowId=wf-uuid
Authorization: Bearer <token>Response (Workflow Execution Record):
{
"id": "we-execution-uuid",
"workflowId": "wf-uuid",
"contentId": "550e8400-e29b-41d4-a716-446655440000",
"dataspaceId": "sds-87654321",
"status": "started",
"startedAt": "2024-10-28T10:31:00Z",
"completedAt": null,
"errorMessage": null
}Ingestion runs asynchronously in the background. Here's what happens:
Sync supports over 40 different file types with specialized extraction methods for each:
Document Formats:
- PDF (with table extraction)
- Microsoft Word (.docx, .doc)
- Microsoft Excel (.xlsx, .xls)
- Microsoft PowerPoint (.pptx, .ppt)
- Plain text (.txt, .md, .csv)
- Rich Text Format (.rtf)
- OpenDocument formats (.odt, .ods, .odp)
Image Formats (with OCR):
- JPEG, PNG, GIF, BMP, TIFF, WebP
- AWS Textract for high-accuracy OCR
- Confidence scoring per text block
CAD & Engineering:
- AutoCAD (.dwg, .dxf)
- SolidWorks (.sldprt, .sldasm)
- Metadata and annotation extraction
Media Formats:
- Video (.mp4, .avi, .mov) - transcript extraction
- Audio (.mp3, .wav) - speech-to-text
Web Formats:
- HTML, EPUB
- Markdown rendering
Archive Formats:
- ZIP, TAR, RAR (extracts and processes contents)
Specialized extraction ensures maximum text quality for each format, preserving tables, layouts, and structure where possible.
Sync uses adaptive chunking strategies optimized for different query types:
Small-Scale Queries (Specific questions):
- Chunk Size: 512-1024 characters
- Overlap: 200 characters
- Strategy: Sentence-aware splitting
- Use Case: "What's the payment term?" → Returns precise excerpt
Large-Scale Queries (Research, summaries):
- Chunk Size: 2048-4096 characters
- Overlap: 400 characters
- Strategy: Section-aware splitting (respects headings, paragraphs)
- Use Case: "Summarize all customer feedback" → Captures full context
Hybrid Approach: Sync generates multiple chunk sizes simultaneously, allowing queries to select the optimal granularity:
-- Small chunks for precise retrieval
document_chunks (
embedding vector(1536),
chunk_size 'small',
chunk_text TEXT -- ~800 chars
)
-- Large chunks for context
document_chunks (
embedding vector(1536),
chunk_size 'large',
chunk_text TEXT -- ~3000 chars
)Vector Embeddings:
- Vector embeddings are generated using the model of the customer's choice. Sync automatically manages indexes over the vector space for maximum performance depending on the Dataspace type
This enables sub-second semantic search across millions of documents.
### Step 3: Precomputed Queries (Ontology-Driven)
If an ontology is defined, Sync automatically runs **user-defined queries** on the content during ingestion. These precomputed queries extract structured data that becomes immediately API or SQL-queryable metadata for the object.
#### Example: Ontology-Defined Queries
```json
{
"ontology": {
"name": "Legal Documents",
"categories": [
{
"id": "cat-contract",
"name": "Contract",
"metadataQueries": [
{
"key": "effectiveDate",
"query": "What is the effective date of this contract?",
"type": "date",
"extractionPrompt": "Extract the effective date in ISO 8601 format"
},
{
"key": "parties",
"query": "Who are the contracting parties?",
"type": "array",
"extractionPrompt": "List all parties to the contract"
},
{
"key": "termLength",
"query": "What is the contract term length in months?",
"type": "number",
"extractionPrompt": "Extract the term length as a number"
},
{
"key": "autoRenewal",
"query": "Does this contract have an auto-renewal clause?",
"type": "boolean",
"extractionPrompt": "Return true if auto-renewal is mentioned"
},
{
"key": "summary",
"query": "Provide a 2-sentence summary of this contract",
"type": "text",
"extractionPrompt": "Summarize the key terms concisely"
}
]
}
]
}
}For each metadata query, Sync:
- Executes the query against the document using an AI agent
- Validates the response type (date, number, boolean, text, array)
- Stores the result in the content's metadata field
- Logs the execution with confidence scores
Result (After Precomputed Queries):
{
"contentId": "550e8400-...",
"fileName": "MSA-AcmeCorp.pdf",
"categoryId": "cat-contract",
"metadata": {
// Original user-provided metadata
"customerName": "Acme Corp",
"internalId": "CONT-2024-0042",
// AI-extracted metadata from precomputed queries
"effectiveDate": "2024-01-15",
"parties": ["Acme Corporation", "Tech Innovations LLC"],
"termLength": 36,
"autoRenewal": true,
"summary": "Master Service Agreement for software development services. Three-year term with annual value of $250,000 and automatic renewal."
},
"inferenceTaskExecutions": {
"effectiveDate": {
"executedAt": "2024-10-28T10:31:15Z",
"confidence": 0.98,
"rawResponse": "The effective date is January 15, 2024"
},
"parties": {
"executedAt": "2024-10-28T10:31:18Z",
"confidence": 0.95,
"rawResponse": "Parties: Acme Corporation and Tech Innovations LLC"
}
},
"status": "ready"
}Via REST API:
# Get specific content with extracted metadata
GET https://sws-12345678.cloud.syncdocs.ai/api/content/sds-87654321/550e8400...
# Filter by extracted metadata
GET https://sws-12345678.cloud.syncdocs.ai/api/content/sds-87654321?
filters={"metadata.autoRenewal":true,"metadata.termLength":{"$gte":24}}Via Direct SQL:
-- Find all contracts with auto-renewal over $200k
SELECT
content_id,
file_name,
metadata->>'customerName' as customer,
(metadata->>'annualValue')::numeric as value,
metadata->>'summary' as summary
FROM content
WHERE category_id = 'cat-contract'
AND (metadata->>'autoRenewal')::boolean = true
AND (metadata->>'annualValue')::numeric > 200000
ORDER BY (metadata->>'annualValue')::numeric DESC;
-- Aggregate analytics on extracted data
SELECT
metadata->>'contractType' as type,
COUNT(*) as count,
AVG((metadata->>'termLength')::numeric) as avg_term_months,
SUM((metadata->>'annualValue')::numeric) as total_value
FROM content
WHERE category_id = 'cat-contract'
AND metadata->>'effectiveDate' > '2024-01-01'
GROUP BY metadata->>'contractType';Under the hood, Sync maintains multiple specialized data stores optimized for different data types needed to power this.
Under the hood, Sync maintains multiple specialized data stores optimized for different data types needed to power the complete workflow, from the raw blob data to structured metadata to vector embeddings. Despite multiple underlying stores, Sync provides a single unified API to access this data:
# Single endpoint retrieves from all stores
GET /api/content/{dataspaceId}/{contentId}
# Returns:
{
"contentId": "...",
"fileName": "...",
"metadata": {...},
"fileUrl": "...",
"thumbnailUrl": "...",
"vectorChunkCount": 24,
"projects": [...]
}After ingestion completes, content is fully prepared for:
Query & Research Agents:
POST /api/content/sds-87654321/query
{
"query": "Find all contracts with auto-renewal clauses expiring in 2025",
"agentId": "research-agent-uuid",
"filters": {
"metadata.autoRenewal": true,
"metadata.effectiveDate": {"$gte": "2024-01-01", "$lt": "2026-01-01"}
}
}Response includes:
- Semantic search results from vector store
- AI-generated answer synthesizing multiple documents
- Citations to source documents
- Extracted metadata for context
SQL-First Applications:
Connect BI tools, analytics platforms, or custom applications directly to the dataspace database:
# Business Intelligence Example (Python + pandas)
import psycopg2
import pandas as pd
conn = psycopg2.connect(workspace_db_url)
# Query extracted metadata for dashboard
df = pd.read_sql("""
SELECT
metadata->>'customerName' as customer,
metadata->>'contractType' as type,
(metadata->>'annualValue')::numeric as value,
(metadata->>'termLength')::numeric as term_months,
metadata->>'effectiveDate' as start_date
FROM content
WHERE category_id = 'cat-contract'
AND (metadata->>'effectiveDate')::date > CURRENT_DATE - INTERVAL '1 year'
""", conn)
# Use in Tableau, PowerBI, or custom dashboardsMetadata Annotation of Remote Repositories:
For detailed information on accessing your data through REST APIs or direct SQL connections, please refer to our API Reference Documentation.
Customer Isolation:
- Each customer has dedicated VPC with unique CIDR range
- VPC peering only between customer VPC and Control Plane
- Zero cross-customer network connectivity
- Private subnets for all databases
Data Encryption:
- At Rest: AES-256 encryption
- In Transit: TLS 1.3 for all API traffic
- VPC Peering: Traffic encrypted by cloud provider
API Authentication:
- JWT bearer tokens for all requests
- Token validation in both Control and Compute planes
- Role-based access control (RBAC)
- Account-level isolation enforced
Database Security:
- No public database access
- Connection pooling with credential rotation
- Query logging for audit trail
- Automated backup encryption
- Data Residency: Customer data stays in designated regions
- GDPR Ready: Data isolation supports data sovereignty
- Audit Logs: Complete trail of all operations
- Backup & Recovery: Automated, encrypted backups
- Understand Dataspaces - Deep dive into data organization
- Learn about Workspaces - Explore compute resources
- Explore Queries - Understand the query interface
- Getting Started Guide - Start building
API Reference See complete API Reference