Sync is an all-in-one document intelligence platform that enables organizations to develop agentic applications on top of unstructured content. Unlike traditional document processing or search solutions, Sync provides a complete infrastructure for building production-ready AI systems that understand, process, and interact with your documents—deployed entirely within your own cloud environment.
__ 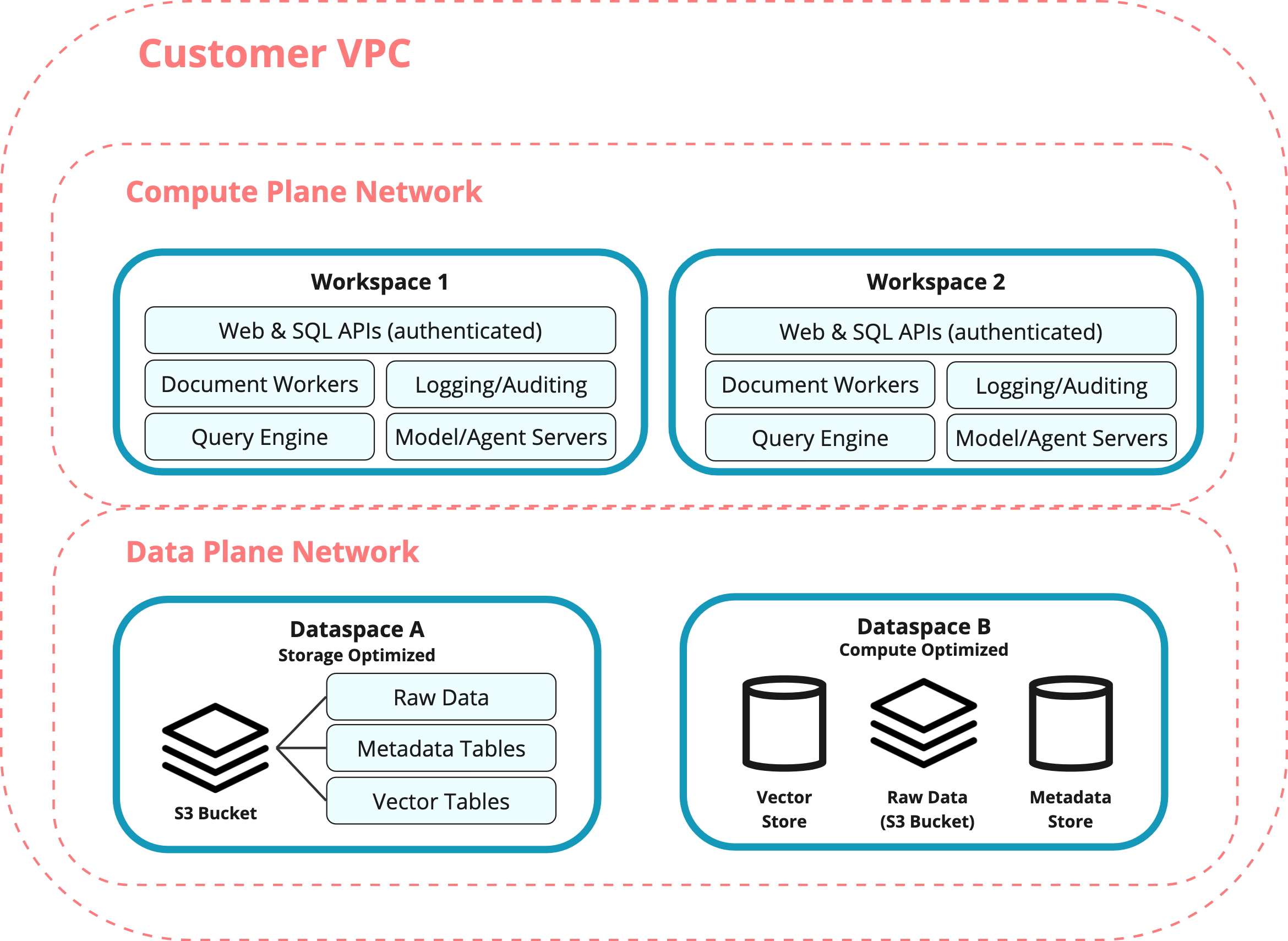 Overview of resources automatically managed by Sync in your own cloud
Overview of resources automatically managed by Sync in your own cloud
__
Sync empowers technical teams to create sophisticated document AI applications without building infrastructure from scratch:
- Production-grade query and research agents Build and host AI agents that understand your domain and answer questions using internal and external content your refine as the source of truth.
- Intelligent data extraction systems Automate the extraction and generation of structured metadata from unstructured documents using AI workflows, including content classification and categorization using nuanced internal rules.
- Enterprise Content Management sytem Build custom ECM systems where AI agents actively manage, organize, and process documents according to your business rules.
Traditional search agents provide generic Q&A over your documents with limited customization:
- ❌ Minimal control over AI behavior and workflows
- ❌ No infrastructure flexibility (SaaS only)
- ❌ Need other solutions to power production-grade document processing pipelines or production applications
- ❌ No uniform data catalog to enforce governance and auditing of agent queries
Sync provides:
- ✅ Full programmable control: Define custom agents, workflows, and processing pipelines through APIs
- ✅ Deploy anywhere: Run in your own cloud account with complete data isolation
- ✅ Beyond search: Extract metadata, classify content, orchestrate multi-step workflows
- ✅ Domain customization: Define custom ontologies, categories, and business logic
IDP frameworks provide libraries and tools but require significant infrastructure and integration work:
- ❌ You build and maintain the entire infrastructure
- ❌ Must integrate vector databases, LLM APIs, storage, queues
- ❌ Requires extensive DevOps and MLOps expertise
- ❌ Hard to scale to single queries spanning thousands or millions of documents
- ❌ No built-in data isolation or access control
Sync provides:
- ✅ Managed infrastructure: Complete document intelligence infrastructure out-of-the-box
- ✅ Auto-configuration: No need to configure chunking strategies, embedding models, or vector indexes
- ✅ Enterprise ready: Built-in data isolation, access control, audit logs, and monitoring
- ✅ Scale effortlessly: Query one document or ten million with the same architecture
Data lakes excel at structured data analytics but struggle with unstructured documents:
- ❌ Documents treated as binary blobs without semantic understanding
- ❌ Complex setup to make documents "AI-ready" and build applications on top of them
- ❌ Require additional solutions for document management, viewing, query editing, etc.
- ❌ Not optimized for real-time document query and retrieval
Sync provides:
- ✅ Native document intelligence and processing: Built specifically for unstructured content
- ✅ AI-first architecture: Effortless text extraction, embedding generation, and semantic indexing
- ✅ Real-time queries: Sub-second semantic search and AI-powered Q&A on top of unstructured documents
- ✅ Rich, effortless document metadata: Support for custom ontologies and automated business-specific classification
- ✅ Transactional & Analytical queries: Use a single platform and query syntax to power a variety of unstructured query use cases
Sync's architecture is designed to make building document AI applications as simple as possible:
Deploy Sync's infrastructure within your own VPC with complete data isolation. Resources can be hosted by Sync (Standard Edition) or in your own cloud accounts (Enterprise Edition).
- Compute Resources (Workspaces): Stateless processing clusters that scale independently from storage
- Storage Resources (Dataspaces): Isolated data segments for different business use cases or tenants. Can choose between options geared for large-scale and long-term archival (storage optimized) or fast query access (compute optimized)
Sync maintains a set of resources in its own VPC. This acts as a control plane that orchestrates resources within the customer environment and serves a UI without having to process internal customer data.
__ 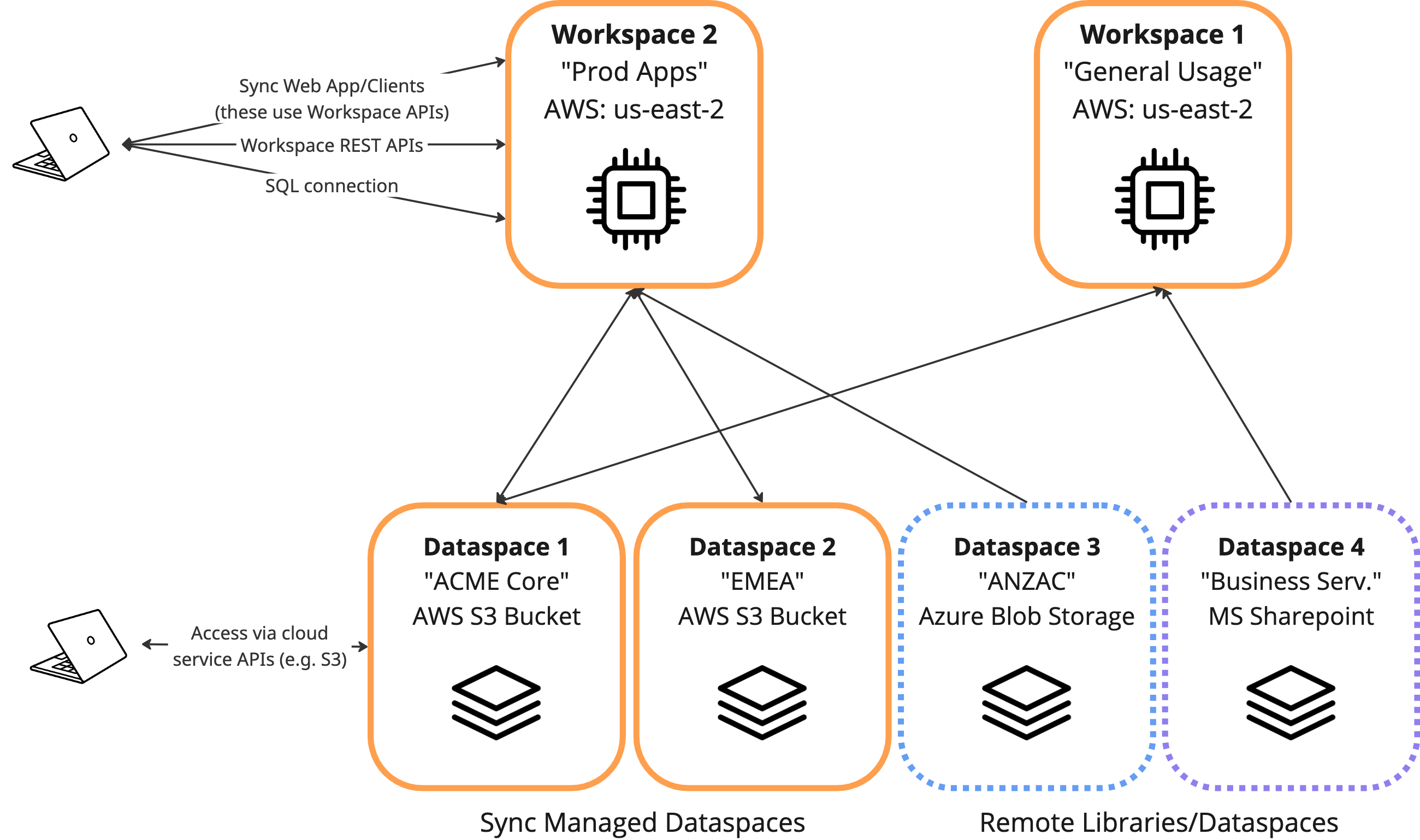 __
__
All infrastructure is provisioned and managed automatically through Sync's Admin API or UI—no manual cloud configuration required.
Bring your documents into Sync from multiple sources:
Dataspaces (Customer Managed) — For content you own and manage in remote repositiories:
- Bulk import from S3, Google Drive, SharePoint
- Continuous sync from content management systems
Dataspaces (Sync Managed) - For content you own and manage inside Sync:
- Upload documents via API or web interface
- Under the hood, Sync stores these in a cloud storage solution within your account
- Full Enterprise Content Management capabilities
Libraries - For internal or external content to add as agent context:
- Scrape and index public websites or intranet content
- Integrate third-party documentation
- Pull in research papers and articles
Once content is ingested, Sync handles all the complexity of making it AI-ready:
- ✅ Universal format support: PDFs, Word, Excel, images, CAD files, videos—no configuration needed
- ✅ Intelligent extraction: Text, tables, images, metadata are extracted automatically
- ✅ Semantic indexing: Vector embeddings generated and indexed for semantic searches of various typess
- ✅ OCR for images: Automatic text extraction from scanned documents and images
- ✅ File derivatives: Generate thumbnails, previews, and optimized formats
- ✅ Bring Your Own Model: Choose from a number of available providers SaaS providers or use internally hosted ones
All processing happens automatically in the background. You don't configure chunking strategies, configure file processing or manage vector and metaadata databases—Sync handles it all.

Within Sync, everything from a research query with citations to document data extraction is modelled as a query. Sync's unified query interface allows you to perform a wide variety of query operations by adjusting scope and context:
Document Data Extraction/Labeling:
{
"query": "Classify this document according or our internal data security classification policy",
"dataspaceId": "sds-12345",
"contentId": <UUID>,
"agentId": [<data-classification-policy-agent-id>]
}Basic Q&A Query:
{
"query": "What are the usual payment terms in our contracts?",
"dataspaceId": "sds-12345"
}Filtered Research Query:
{
"query": "Summarize all policy changes from Q4 2024",
"dataspaceId": "sds-12345",
"filters": {
"categories": ["policy-document"],
"metadata": { "quarter": "Q4", "year": "2024" }
},
"agentId": <research-agent-uuid>
}Multi-Source Query with Libraries:
{
"query": "Compare our internal policies against industry standards and regulations",
"dataspaceId": "sds-12345",
"libraries": ["lib-industry-standards", "lib-regulations"],
"includeWebSearch": true
}The same query interface powers everything from simple document search to complex research workflows.
Sync provides additional building blocks to create sophisticated document AI applications:
Agents - Define custom AI assistants with specific instructions, context, and permissions
- Research agents for comprehensive document analysis
- Classification agents for content categorization
- Extraction agents for structured data retrieval
Ontologies - Define your domain's structure
- Categories (document types)
- Metadata queries (custom fields)
- Validation rules and constraints
Workflows - Orchestrate multi-step document processing
- Sequential task execution
- Conditional branching
- Human-in-the-loop review steps
Projects - Organize content by business process
- Group related documents
- Track processing status
- Manage access control
Policies - Enforce governance and compliance
- Access control rules
- Retention policies
- Audit requirements
Sync's three-tier architecture ensures scalability, isolation, and flexibility. Read more about our architecture.
Sync supports flexible deployment models to meet your security and compliance requirements:
SaaS - Fully managed in Sync's cloud accounts
- Fastest time to value
- Automatic updates and maintenance
- Usage-based pricing
PaaS - Deploy in your own AWS/GCP/Azure account
- Complete data isolation
- Meet data residency requirements
- Full infrastructure control
- Sync manages software updates
- Usage-based pricing
Ready to build your first document AI application? Here's how to get started:
- Getting Started Guide - Step-by-step setup instructions
- Explore Core Concepts - Understand Sync's architecture and components
- Follow a Guide - Build your first query agent or processing pipeline
- API Reference - Dive into the complete API documentation